x <- c(TRUE, FALSE, TRUE, TRUE, FALSE)
typeof(x)
#> [1] "logical"
length(x)
#> [1] 58 Logic and control flow
In Section 4.3, you saw that TRUE becomes 1 and FALSE becomes 0 when R needs a number. That was a hint. Logical values are not second-class citizens in R; they are a full type with their own operators, and they drive every decision your code makes. This chapter covers logical vectors, comparisons, boolean operators, and if/else. In R, if/else is an expression that returns a value, not a statement that directs traffic.
8.1 Logical vectors
TRUE and FALSE are R’s logical values. You already met them in Section 4.2 as one of the four main types (double, integer, character, logical).
Every comparison you write, every filter you apply, every conditional check you run produces one of these vectors. The trick from Section 4.3 is what makes expressions like sum(x > 5) work: x > 5 produces a logical vector, sum() coerces TRUE to 1 and FALSE to 0, and suddenly you are counting how many elements pass the test without writing a single loop.
A logical value is one of exactly two things: TRUE or FALSE. No third option, no grey area, no maybe. What happens, then, when someone overrides one of the two options?
NoteSum types
In type theory this is a sum type (also called a tagged union or variant): a type defined by listing its variants, so that Bool = TRUE | FALSE. Contrast this with a data frame row, which combines fields with AND (a penguin has a species AND a mass AND a flipper length); a sum type chooses one variant with OR. You will see sum types surface again when factors define a fixed set of levels (Section 12.4) and when S3 dispatch selects a method based on class (Section 24.2). Where product types say “all of these together,” sum types say “exactly one of these.”
R has T and F as shortcuts for TRUE and FALSE. Do not use them.
T <- 42
T
#> [1] 42rm(T)T is a regular variable name, so you can overwrite it with anything, and R will not complain. TRUE is a reserved word, locked and immutable. Code that relies on T meaning TRUE will break silently the moment someone (or some package) assigns to T, and the same applies to F.
TipOpinion
Never use T and F. Always write TRUE and FALSE in full. If someone reassigns T, your filter returns the wrong rows and nothing throws an error.
Exercises
- What does
sum(c(TRUE, FALSE, TRUE, FALSE, TRUE))return? Why? - What is
typeof(TRUE)? What abouttypeof(T)(before any assignment)? - Try
TRUE <- 42. What happens?
8.2 Comparison operators
Six operators compare values:
3 == 3
#> [1] TRUE
3 != 4
#> [1] TRUE
3 < 5
#> [1] TRUE
3 > 5
#> [1] FALSE
3 <= 3
#> [1] TRUE
3 >= 4
#> [1] FALSEAll six are vectorized:
x <- c(1, 5, 3, 8, 2)
x > 3
#> [1] FALSE TRUE FALSE TRUE FALSEFive values in, five logical values out, following the same vectorization from Section 4.4 but applied to comparisons instead of arithmetic.
%in% tests membership in a set:
x <- c("cat", "dog", "bird", "cat")
x %in% c("cat", "bird")
#> [1] TRUE FALSE TRUE TRUECompare x == "cat" | x == "bird" to x %in% c("cat", "bird"): both produce the same result, but %in% scales gracefully to larger sets without forcing you to chain == and | over and over.
One trap deserves early mention. Try this:
0.1 + 0.2 == 0.3
#> [1] FALSEFALSE. Computers store numbers in binary, and most decimal fractions have no exact binary representation (the same way 1/3 has no exact decimal representation). The stored values of 0.1 + 0.2 and 0.3 differ by about 5.6e-17, an invisible speck of rounding error that == faithfully detects. Use all.equal() for approximate comparison:
all.equal(0.1 + 0.2, 0.3)
#> [1] TRUEChapter 6 covers floating-point arithmetic in depth, including catastrophic cancellation, condition numbers, and log-space arithmetic. For now, the rule is simple: never use == to compare computed decimal numbers. But if you cannot trust == for decimals, how do you combine multiple conditions safely?
Exercises
- What does
c(1, 2, 3) == c(1, 5, 3)return? - Use
%in%to check which elements ofc("a", "b", "c", "d")are vowels. - What does
0.1 + 0.1 + 0.1 == 0.3return? Is it the same as0.1 + 0.2 == 0.3? Why?
8.3 Boolean operators
Logical values combine with & (and), | (or), and ! (not):
TRUE & FALSE
#> [1] FALSE
TRUE | FALSE
#> [1] TRUE
!TRUE
#> [1] FALSEThese are vectorized, like arithmetic:
x <- c(1, 5, 3, 8, 2)
x > 2 & x < 6
#> [1] FALSE TRUE TRUE FALSE FALSEEach element is tested independently: is it greater than 2 and less than 6?
R also has && and ||, which look similar but behave very differently. They examine only the first element of each operand and use short-circuit evaluation: if the left side of && is FALSE, the right side is never touched, because the result must be FALSE regardless of what the right side contains. The same logic applies to || when the left side is TRUE.
FALSE && stop("this is never reached")
#> [1] FALSENo error. stop() was never called because && saw FALSE on the left and skipped everything to the right. Compare that to the single-ampersand version:
FALSE & stop("this IS reached")
#> Error:
#> ! this IS reached& evaluated both sides, so stop() fired.
TipOpinion
Use & and | when working with vectors (filtering data, logical indexing). Use && and || inside if() conditions, where you have a single logical value and want short-circuit behavior.
xor() (exclusive or) returns TRUE when exactly one of its arguments is TRUE:
xor(TRUE, FALSE)
#> [1] TRUE
xor(TRUE, TRUE)
#> [1] FALSEYou won’t need xor() often, but it exists. These four operations, &, |, !, and xor(), are not just software conventions; they correspond directly to the logic gates wired into every processor, described by the same truth tables George Boole formalized in 1854.
Exercises
- What does
c(TRUE, FALSE, TRUE) & c(TRUE, TRUE, FALSE)return? - What does
TRUE | stop("error")do? What aboutTRUE || stop("error")? Explain the difference. - Write a logical expression that tests whether
xis between 10 and 20 (inclusive).
NoteFrom logic gates to circuits
The & you typed a moment ago to combine filter conditions is the same AND operation that electrical engineers wire into silicon. In his 1937 master’s thesis, Claude Shannon showed that these truth tables could be implemented with electrical switches, and that insight bridged the gap between abstract algebra and physical circuitry. Every digital circuit is built from these operations.
An AND gate has two input wires and one output wire; the output is 1 (high voltage) only when both inputs are 1. An OR gate outputs 1 when at least one input is 1. A NOT gate (also called an inverter) has one input and flips it: 1 becomes 0, 0 becomes 1. An XOR gate outputs 1 when the inputs differ.
AND gate OR gate XOR gate NOT gate
A B out A B out A B out A out
0 0 0 0 0 0 0 0 0 0 1
0 1 0 0 1 1 0 1 1 1 0
1 0 0 1 0 1 1 0 1
1 1 1 1 1 1 1 1 0These are the same truth tables as R’s &, |, xor(), and !. When you write TRUE & FALSE in R, the CPU evaluates it using an AND gate (or a chain of them, for vectors).
Everything a computer does, from adding numbers to rendering video, is built from combinations of these four gates. We can design a circuit the way electrical engineers do: start with inputs and outputs, build a truth table, find the minimal Boolean expression, then wire the gates.
NoteDesigning a half adder
The simplest possible addition: two single bits, A and B. Two outputs: a sum bit and a carry bit (because 1 + 1 = 10 in binary, which is 0 with a carry of 1).
Step 1: truth table. List every possible input combination and the desired output.
A B | Sum Carry
0 0 | 0 0
0 1 | 1 0
1 0 | 1 0
1 1 | 0 1Step 2: Boolean expression. For each output, read off the rows where it equals 1. Write each row as a product (AND) of the inputs, using NOT for 0s. Then combine the rows with OR. This is called the sum of minterms, the canonical form for any Boolean function:
Sum = (NOT A AND B) OR (A AND NOT B)
Carry = A AND BSum is 1 in two rows: when A=0, B=1 (that’s NOT A AND B) and when A=1, B=0 (that’s A AND NOT B).
Step 3: minimize. The canonical form is correct but not always efficient. Look at Sum: it is 1 when A and B differ, which is the definition of XOR. So:
Sum = A XOR B
Carry = A AND BTwo gates. This is a half adder. Before looking at the circuit, here are the standard symbols used in circuit diagrams. A filled dot where wires cross means they are connected (a junction); without the dot, wires simply cross without connecting.
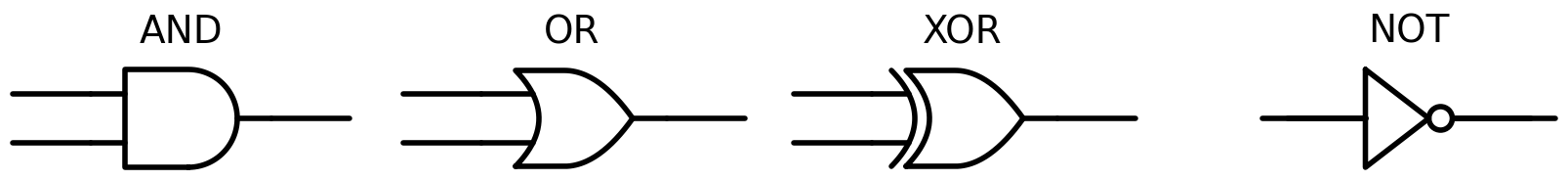
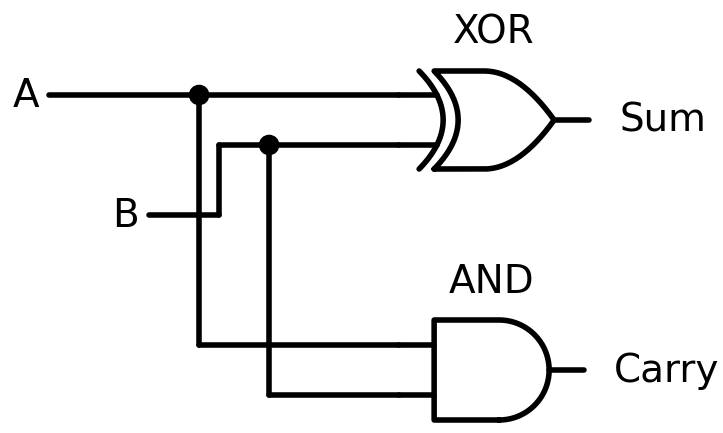
We can verify this in R, since R’s &, |, !, and xor() are the same Boolean operations:
half_adder <- function(A, B) {
list(Sum = xor(A, B), Carry = A & B)
}
half_adder(FALSE, FALSE)
#> $Sum
#> [1] FALSE
#>
#> $Carry
#> [1] FALSE
half_adder(TRUE, FALSE)
#> $Sum
#> [1] TRUE
#>
#> $Carry
#> [1] FALSE
half_adder(TRUE, TRUE)
#> $Sum
#> [1] FALSE
#>
#> $Carry
#> [1] TRUETRUE + TRUE gives Sum = FALSE (0), Carry = TRUE (1). That’s binary 10: the number 2. But real addition involves three inputs, not two.
NoteFrom half adder to full adder
When you add column by column in decimal, you carry from the previous column. Binary works the same way: each column receives A, B, and a carry-in (Cin) from the column to the right.
Step 1: truth table. Three inputs, eight rows.
A B Cin | Sum Cout
0 0 0 | 0 0
0 0 1 | 1 0
0 1 0 | 1 0
0 1 1 | 0 1
1 0 0 | 1 0
1 0 1 | 0 1
1 1 0 | 0 1
1 1 1 | 1 1Step 2: sum of minterms. Read off rows where each output is 1:
Sum = (NOT A AND NOT B AND Cin) OR (NOT A AND B AND NOT Cin)
OR (A AND NOT B AND NOT Cin) OR (A AND B AND Cin)
Cout = (NOT A AND B AND Cin) OR (A AND NOT B AND Cin)
OR (A AND B AND NOT Cin) OR (A AND B AND Cin)Four terms per output, each with three variables. A mess.
Step 3: minimize with a Karnaugh map. A Karnaugh map (K-map) is a visual tool for simplifying Boolean expressions. You arrange the truth table rows in a grid so that adjacent cells differ by exactly one input, then look for rectangular groups of 1s: each group of 2, 4, or 8 adjacent 1s can be collapsed into a simpler term.
K-map for Cout, with AB on one axis and Cin on the other:
AB
Cin 00 01 11 10
0 | 0 0 1 0
1 | 0 1 1 1Three groups of two 1s emerge: the column AB=11 (group: A AND B, regardless of Cin), the row Cin=1 with B=1 (group: B AND Cin), and the row Cin=1 with A=1 (group: A AND Cin). The minimal expression:
Cout = (A AND B) OR (B AND Cin) OR (A AND Cin)Much simpler than the four-term canonical form. For Sum, the K-map shows no adjacent groups (the 1s form a checkerboard), so there’s no simplification beyond XOR:
Sum = A XOR B XOR CinStep 4: build the circuit. The Sum formula chains two XOR gates. The Cout formula uses two AND gates and one OR gate, but engineers noticed that (B AND Cin) OR (A AND Cin) can be rewritten as ((A XOR B) AND Cin), because the XOR captures whether exactly one of A, B is 1. The final circuit uses five gates: two XOR, two AND, one OR.
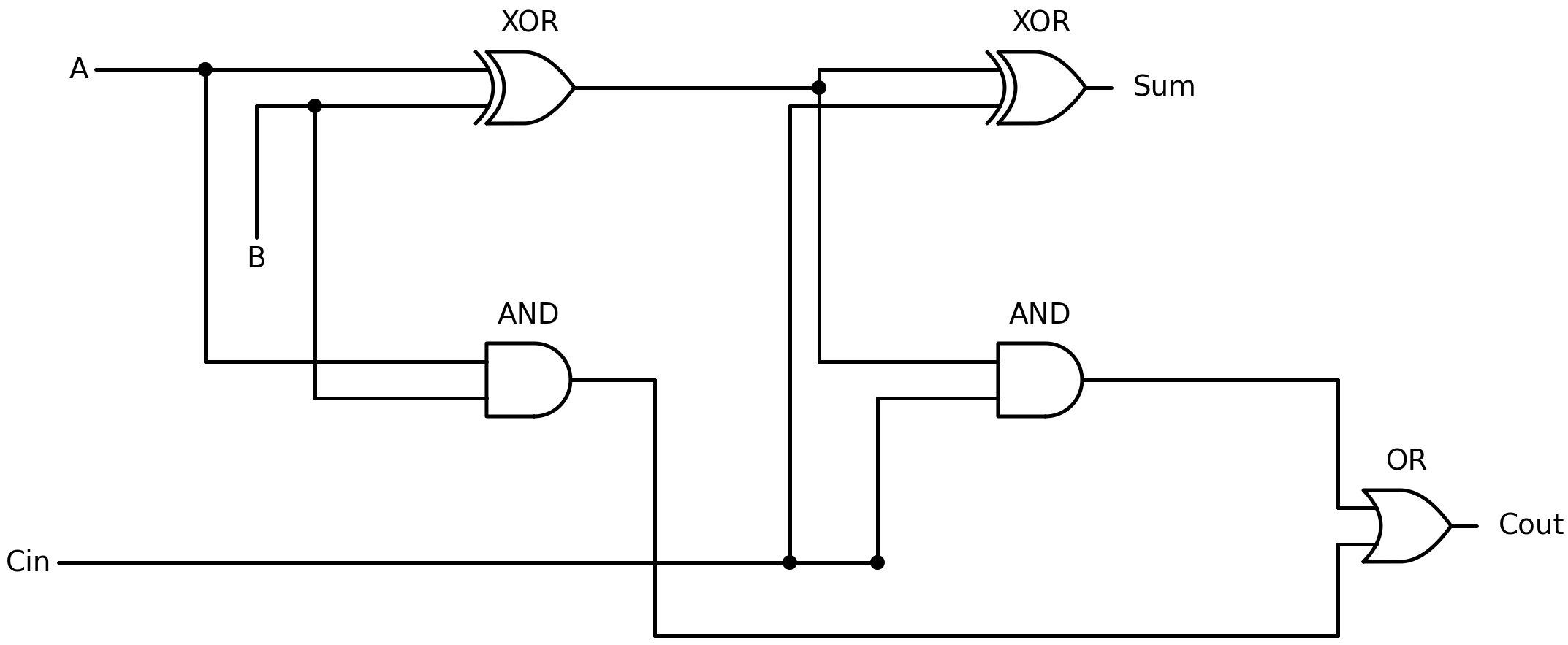
full_adder <- function(A, B, Cin) {
p <- xor(A, B) # partial sum (first XOR)
Sum <- xor(p, Cin) # final sum (second XOR)
Cout <- (A & B) | (p & Cin) # carry-out
list(Sum = Sum, Carry = Cout)
}
full_adder(TRUE, TRUE, FALSE) # 1+1+0 = 10 binary
#> $Sum
#> [1] FALSE
#>
#> $Carry
#> [1] TRUE
full_adder(TRUE, TRUE, TRUE) # 1+1+1 = 11 binary
#> $Sum
#> [1] TRUE
#>
#> $Carry
#> [1] TRUE1 + 1 + 0 = 2 (binary 10: Sum=0, Carry=1). 1 + 1 + 1 = 3 (binary 11: Sum=1, Carry=1).
Chain four full adders together, each one’s Cout feeding the next one’s Cin, and you have a 4-bit adder. Chain 64 of them and you can add two 64-bit numbers. A CPU is billions of these gates arranged to perform arithmetic, comparisons, and memory access. The & you use to filter penguins (body_mass_g > 4000 & species == "Gentoo") runs on these same gates.
The workflow we followed (truth table, canonical form, minimize, circuit) is called Boolean function minimization. K-maps work for up to four or five inputs; for larger circuits, algorithms like Quine-McCluskey or Espresso take over. The principle, though, is always the same: specify what you want as a truth table, then find the smallest set of gates that produces it.
A logic gate on its own computes one result and stops, frozen in time. Add a clock (an electrical signal that alternates between 0 and 1 at a fixed rate, say three billion times per second) and flip-flops (gates that remember their output until the next clock tick), and the circuit can feed its result back into itself as the next input. With feedback, static logic becomes computation. The calculator from Section 1.1 that added 3 + 5 + 2 + 8 by keeping a running total? It is an adder circuit driven by a clock, reading one number per tick, feeding the output back into the input. Every processor is this idea, scaled up.
8.4 How numbers are stored
R has double and integer types (Section 4.2), and for most day-to-day work you never think about the difference. But the computer thinks about it constantly, because the two types are stored in fundamentally different ways.
Everything is bits: 0s and 1s. An integer is stored as a binary number, so the integer 42 in binary is 101010:
1 0 1 0 1 0
2⁵ 2⁴ 2³ 2² 2¹ 2⁰
32 16 8 4 2 1
32 + 0 + 8 + 0 + 2 + 0 = 42Each position represents a power of 2: a 1 means “include this power,” a 0 means “skip it.” R uses 32 bits for an integer, so the largest integer is 231 - 1 = 2,147,483,647 (one bit is reserved for the sign, positive or negative).
.Machine$integer.max
#> [1] 2147483647A double (also called a floating-point number) is stored differently, using 64 bits split into three parts: 1 bit for the sign, 11 bits for the exponent, and 52 bits for the fraction (called the significand):
[sign] [exponent: 11 bits] [significand: 52 bits]
1 bit determines determines
+/- the scale the precisionThe number is reconstructed as: ± fraction × 2exponent. This format (IEEE 754) can represent very large numbers (up to about 1.8 × 10308) and very small ones (down to about 2.2 × 10-308), but not all numbers exactly, which is exactly the trap that bit us with 0.1 + 0.2.
.Machine$double.xmax
#> [1] 1.797693e+308
.Machine$double.xmin
#> [1] 2.225074e-308The 52-bit significand stores the closest binary approximation of each decimal number; when you add two approximations, rounding errors accumulate. Chapter 6 covers these traps in detail, including how to detect them with sprintf("%.20f", ...) and how to avoid them with all.equal() and dplyr::near().
R defaults to double for all numbers unless you add the L suffix:
typeof(42)
#> [1] "double"
typeof(42L)
#> [1] "integer"42 is a 64-bit floating-point number; 42L is a 32-bit integer. For most data analysis, the distinction is invisible, until you compare computed values with == or work with very large counts. But now that you understand how R stores and compares values, the question shifts: how does R act on the results of those comparisons?
8.5 if/else as an expression
In most languages, if/else is a statement: it controls which code runs but does not produce a value. In R, if/else is an expression: it evaluates to the value of whichever branch is taken, and you can assign that value directly.
x <- -3
y <- if (x > 0) "positive" else "non-positive"
y
#> [1] "non-positive"if (x > 0) "positive" else "non-positive" evaluated to "non-positive", and that value was assigned to y. This follows from Section 3.4: everything in R is an expression, and expressions return values. if/else is no exception.
Multi-line branches use curly braces, and the value of each branch is the last expression evaluated inside it:
classify <- function(x) {
if (x > 0) {
label <- "positive"
label
} else if (x == 0) {
"zero"
} else {
"negative"
}
}
classify(5)
#> [1] "positive"
classify(0)
#> [1] "zero"
classify(-2)
#> [1] "negative"R has no elif keyword; you chain conditions with else if, which is just an else followed by another if. Long chains get hard to read, and when you have more than two or three branches, consider switch() (Section 8.7) or dplyr::case_when() (Section 8.6).
The connection to lambda calculus runs deeper than it might seem. In Chapter 22, we saw Church’s encoding of booleans, where TRUE = λx. λy. x (pick the first) and FALSE = λx. λy. y (pick the second). R’s if/else does the same thing: it takes a condition and two branches, and returns whichever branch the condition selects, just as Church’s booleans select an argument.
if (c(TRUE, FALSE)) "yes"
#> Error in `if (c(TRUE, FALSE)) ...`:
#> ! the condition has length > 1if expects a single logical value. If you give it a vector, R uses only the first element and warns you. But data analysis rarely involves a single value; you usually need to test every element of a column at once. So what do you reach for when if/else won’t scale?
Exercises
- What does
if (TRUE) 1 else 2return? What aboutif (FALSE) 1 else 2? - Write a function
sign_labelthat takes a number and returns"positive","zero", or"negative". - What does
if (NA) "yes" else "no"produce? Why?
8.6 Vectorized conditionals
if/else works on a single value. ifelse() works on vectors:
x <- c(-2, 0, 3, -1, 5)
ifelse(x > 0, "pos", "neg")
#> [1] "neg" "neg" "pos" "neg" "pos"For each element, ifelse() checks the condition and returns the corresponding value from the second or third argument, vectorized in the same way + and > are (Section 4.4).
But ifelse() has a weakness: it doesn’t check types.
ifelse(TRUE, 1, "no")
#> [1] 1
ifelse(FALSE, 1, "no")
#> [1] "no"One call returns a number, the other a string. The return type depends on which branch is taken, and that can change silently when your data changes. dplyr::if_else() is stricter:
dplyr::if_else(TRUE, 1, "no")
#> Error in `dplyr::if_else()`:
#> ! Can't combine `true` <double> and `false` <character>.It refuses to mix types, catching bugs early rather than letting them propagate downstream.
For multiple conditions, dplyr::case_when() replaces nested ifelse() chains:
x <- c(-2, 0, 3, -1, 5)
dplyr::case_when(
x > 0 ~ "positive",
x == 0 ~ "zero",
x < 0 ~ "negative"
)
#> [1] "negative" "zero" "positive" "negative" "positive"Each line is a condition-value pair, evaluated in order; case_when() returns the value for the first condition that matches. Compare this to the nested version:
ifelse(x > 0, "positive", ifelse(x == 0, "zero", "negative"))Both produce the same result, but case_when() is easier to read, easier to extend, and harder to get wrong.
TipOpinion
Prefer dplyr::case_when() over nested ifelse(). Nesting ifelse() calls creates code that is hard to read and easy to break when you add a condition; case_when() scales cleanly to any number of branches.
Exercises
- Use
ifelse()to replace negative values inc(-3, 5, -1, 8, 0)with zero. - Use
dplyr::case_when()to classifypenguins$body_mass_ginto"light"(under 3500),"medium"(3500-5000), and"heavy"(over 5000). Don’t forgetNAs. - What happens if no condition matches in
case_when()? Test it.
8.7 switch()
When you need to dispatch on a single string value, switch() is cleaner than a chain of if/else if:
describe <- function(day) {
switch(day,
Monday = "start of the week",
Friday = "almost there",
Saturday = ,
Sunday = "weekend",
"just another day"
)
}
describe("Friday")
#> [1] "almost there"
describe("Saturday")
#> [1] "weekend"
describe("Wednesday")
#> [1] "just another day"Each name is matched against the input. Saturday = with no value falls through to the next case (Sunday), so both return "weekend". The unnamed last entry is the default.
switch() only works with a single string (or number, but string dispatch is the common use). For vector operations, use case_when(). For complex branching logic, use if/else if. switch() fills the narrow gap where you have one value and several named options, and it fills it well. But the real lesson of this chapter is not about any single function. From logical vectors through comparison operators, boolean algebra, and conditional expressions, you have traced a single thread: the idea that every computation reduces to choosing between two values, TRUE or FALSE, 1 or 0, high voltage or low. The if/else in your R script and the AND gate in your CPU are expressions of the same underlying logic, separated by layers of abstraction but never by kind. The next chapter picks up where that thread leads: what happens when you need to make the same choice not once but thousands of times, across every row of a data frame, without writing a single loop.